Managing Research Data
Every research endeavor creates data.
North Dakota State University has a responsibility to steward the data you create during the course of your research. But, as the researcher, you need to make sure your data is in a state that will be useable for all the future researchers who will build on your work.
It is up to you to ensure your data remains useful, and you only need to take a few simple steps to make that happen.
- Consider your long-term plan
-
What to do:
Start by asking yourself these questions:
- What will you keep?
- How long will it be kept?
- Where will it exist?
- Who will pay for the storage?
- What kinds of reuse or sharing will be allowed?
- If there is to be an embargo on availability, how will that be managed, and in what timeframe?
Document your answers to these questions so that you can plan how to manage your data in the future. This information will also be useful to use in creating your data management plan.
Why this is important:
Creating a plan now for what will happen with your data when your research is finished will not only help you to conceptualize how to organize the data as you generate it, but also make it easier to find it when you need to access it.
- Always keep original data and implement a process for version control
-
What to do:
- Maintain original data in a separate folder.
- Use version control of all research data at regular intervals and before new stages in the process.
Why this is important:
Research is typically derived from one or more datasets. Maintaining an unmodified copy of this is necessary for reproducibility. Version control can be very useful, especially if a misstep is made in the research process - it is a complete snapshot of your work at a point in time. Using version control will allow you to revert to an earlier point.
- Backup data regularly (automate this if at all possible)
-
What to do:
Maintain backups in one or more separate physical locations. If you are storing your primary data on a NDSU server, a good backup location may be on an external drive or a cloud-based platform. Some services, including those at NDSU, may be backed up, but the backup scheme may not be sufficient for your research. This document explains storage options available to all NDSU researchers. A consultation with Kim Owen, Program Manager, Research & Education Network Resources, may help determine the best options for your research - 701.231.9522, kim.owen@ndsu.edu.
Why this is important:
If something happens to the computer used to store your original data (e.g. it gets damaged, corrupted, stolen, etc.), you will not lose all of your work.
- Document your data thoroughly (metadata, data dictionary)
-
What to do:
Identify and annotate all data field headings. Be as thorough as possible in describing from where the data is sourced. This is important if your data is to be reused or shared with others, especially if your field naming includes abbreviations or placeholders. Include unaccounted for variables that may affect the outcome or skew the data
Why this is important:
Documentation is important for the following reasons:
- The researcher doesn't always accurately remember what a data field represents. It is better to fully document what a field represents than rely on memory, especially for long-term projects.
- Data use/reuse without assistance
- The research results can be duplicatable
- Clarity about what the data represents, how is was collected, and any variables that were or were not accounted for in data collection
- Cite any secondary data used
-
What to do:
Follow standardized methods for citing data sources.
Why this is important:
Data is increasingly being recognized as a publication type similar to journal articles and books
- Once your project is complete, store and share your data appropriately
-
What to do:
Follow NDSU, funder, and your field’s best practices on where and how you store your data. For more information see: http://libguides.lib.msu.edu/citedata
Follow NDSU, funder, and your field’s best practices on where and how you share your data. Include both short and long-term planning.
For long-term storage, consider a service that will provide you with a DOI for your data. For more information see: https://library.uic.edu/help/article/1966/what-is-a-doi-and-how-do-i-use-them-in-citations/
If your research funder requires that your data be shared and it includes personal and/or proprietary information that falls under FERPA, HIPAA, or other privacy or legal protection rules, create anonymized sharing versions of the final datasets.
Why this is important:
- Grant and legal compliance
- Verification and duplication of research findings
- Implement your long-term plan
-
What to do:
See the plan you created in the first section
Why this is important:
It will help your research future by allowing your work to be duplicated and allow the data to be reused by others.
Writing Your Data Management Plan
Data Management Planning Guide
A data management plan (DMP) is a document that outlines how you will manage data related to your research/project. This may include plans for collecting, organizing, documenting, analyzing, preserving, and sharing the data. Creating and following a plan for managing your data throughout the life-cycle of your research can save time, increase research impact, and ensure long-term ability to preserve and access data. In addition, many funding agencies require a DMP as part of the grant application.
Below are tips for writing your DMP and options for using the NDSU Repository for sharing your data (including boilerplate text you can use in your DMP). You can also consult with your NDSU subject librarian throughout the process if questions arise.
Checklist for Writing Your DMP
- Review principles and standards of data management listed above.
- Review funder requirements for data management.
- Determine how data will be:
- generated, collected, and analyzed (what types of data, in what formats, by what methods, using what software, etc.)
- documented and described (standards, data dictionary, readme file, etc.)
- organized, stored, and protected
- preserved/archived
- accessed and shared (NDSU Repository, discipline-specific repositories, etc.)
- Write the data management plan
- Consult with your NDSU subject librarian throughout the process if questions arise
Tools and Tips for Writing Your DMP
Check out the DMP Tool for examples and templates for DMPs by funding agency. With a DMP Tool account you can create and write your DMP with guidance and tips for each section, based on funding agency requirements. When working with a template within the DMP, you can:
- Enter details of the project (title, fund, grant number, abstract, and PI details)
- Review the titles and descriptions of sections required for your DMP by the funding agency
- Write the DMP section by section
- Share (or not) your plan with others (e.g. private, collaborators, organization, public)
- Download your plan (in PDF, CSV, HTML, TXT, or DOCX)
The Write Plan tab breaks down the DMP into sections required by the funding agency. Within each section there is a box for you to type your content with some formatting options. Not sure exactly what to include in each section? Check out the Guidance tabs.
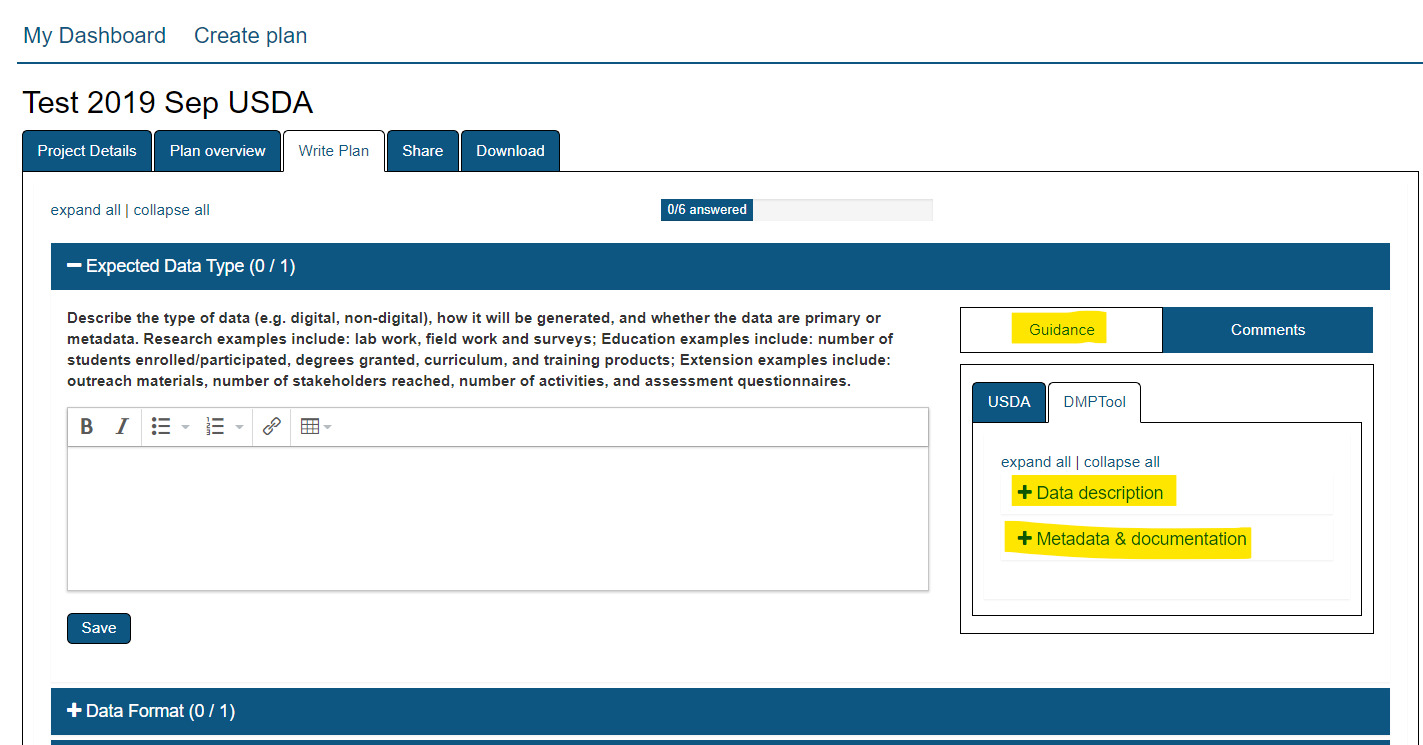 x
x
While working through each section, consider the following questions for each category described in the DMPTool guidance. It is in your best interest that your Data Management Plan address as many of these questions as possible.
Adapted with permission from University of Minnesota's DMP Template from the Data Repository for University of Minnesota (DRUM).Questions to Answer as You Prepare to Write Your DMP:
- Data Description / Data Format / Data Volume
-
- What type of data will be produced? examples of data types
- How will data be collected? In what formats? examples of file formats
- Will it be reproducible? What would happen if it got lost or became unstable later?
- How much data will it be, and at what growth rate? How often will it change?
- Are there tools or software needed to create/process/visualize the data?
- Will you use pre-existing data? From where?
- Metadata & Documentation
-
- How will data collection be documented? Why should you document your data? and how?
- What standards will be used for documentation and metadata?
- What formats or tools will be used for data documentation?
- What directory and file naming convention will be used?
- What project and data identifiers will be used?
- Is there a community standard for metadata sharing/integration?
- Preservation, Storage & Security
-
- Where and how often will you store data? NDSU options: NDSU Repository, CCAST, Central File Services (Google Drive, OneDrive, etc.)
- How will data be archived for preservation and long-term access?
- How long should it be retained? (e.g. 3-5 years, 10-20 years, permanently)
- What file formats will the data be stored in? Are they long-lived formats?
- Are there data archives or repositories that are appropriate for your data?
- Who will maintain the data for the long-term?
- Ethics & Privacy
-
- What steps will be taken to protect privacy, security and confidentiality?
- Does your data have any access concerns? Describe the process someone would take to access your data.
- Who controls the data? (e.g. PI, student, lab, University, funder)
- Are there any special privacy or security requirements? (e.g. personal data, high-security data)
- Any embargo periods to uphold?
- Intellectual Property Rights
-
- What steps will be taken to protect intellectual property rights?
- Does your data have any access concerns?
- Who controls the data?
- Are there any special privacy or security requirements?
- Data Sharing / Data Repository
-
- If you allow others to access your data, how will the data be discovered and shared?
- Consider using the NDSU Repository
- Are there any sharing requirements? (e.g. funder requirements)
- When will data be published and where?
- What tools or software are needed to work with the data?
- If you allow others to access your data, how will the data be discovered and shared?
- Roles & Responsibilities
-
- Who will collect, describe, store, and share the data?
- See DataONE's Best Practices for defining data management roles and responsibilities - e.g. data collector, metadata generator, data analyzer, project director, etc.
- Budget
-
- What tools and resources are needed to follow the data management plan? (e.g. storage costs, hardware, software, staff time, repository charges)
Using the NDSU Repository to Share and Store Your Data
The NDSU Repository is the university’s open access repository for scholarly output and data sharing that enables long-term access and preservation.
NDSU researchers may submit data to the NDSU Repository subject to the following submission criteria:
- Data must be authored by at least one North Dakota State University researcher with an active NDSU ID.
- Data must be non-restricted data that DO NOT contain any private, confidential, or other legally protected information (e.g., personal identifiable information). For further information, see the North Dakota University System Data Classification and Information Security Standard.
- Data must be deposited for open access. Authors will have the option of restricting access for a limited period of time.
- Data are digital, and each file must not exceed 1 GB.
- Data must include adequate documentation describing the nature of the data at an appropriate level for purposes of reuse and discovery. All data receive curatorial review and data that are incomplete or not ready for reuse may not be accepted into the repository.
- The data should be in a final or published state. For active or changing data, use an NDSU storage solution listed on the NDSU ITS website.
Boilerplate Language for Using the NDSU Repository in Your DMP
If appropriate for your data, use this boilerplate language in your DMP to demonstrate your institutionally supported strategy for data sharing and preservation:
A long-term data sharing and preservation plan will be used to store and make publicly accessible the data beyond the life of the project. The data will be deposited in the NDSU Repository (library.ndsu.edu/ir). This repository, hosted by NDSU Libraries (library.ndsu.edu), is an open access platform allowing for the dissemination and archiving of university scholarly output data. Curators review all incoming submissions and work with data authors to comply with data sharing requirements in ways that make data FAIR (Findable, Accessible, Interoperable, Reusable). The NDSU Repository provides long-term preservation of digital objects using services such as migration (limited format types), off-site backup, bit-level checksums, and assigns a Uniform Resource Identifier (URI) for archival citations (a Handle.net identifier and/or DOI). The data will be accompanied by the appropriate documentation, metadata, and code to facilitate reuse and provide the potential for interoperability with similar data sets.
- Glossary of Data Management Terms
-
Annotation: a note of explanation or comment added to a data field heading
Backup: a copy of one or more files created as an alternate in case the original data is lost or becomes unusable
CCAST: Center for Computationally Assisted Science and Technology - an NDSU research unit that supports NDSU research, and provides onsite hardware, software, and filesystems for researchers and their private and public sector partners.
Cloud-based platform: a computing platform that delivers its services via the internet; resources are available for computing, storage, and networking: https://www.sdxcentral.com/cloud/definitions/what-is-cloud/
Controlled vocabulary: standardized and organized arrangements of words and phrases that provide a consistent way to describe data. Users of controlled vocabulary lists select terms that offer preferred or authorized terms and spellings which improves information retrieval by reducing the quantity and ambiguity of terms, and ensuring consistency in application: https://en.wikipedia.org/wiki/Controlled_vocabulary
Data citation: the practice of providing a reference to data in the same way as researchers routinely provide citations for things like journal articles, reports, and conference reports. Data citation is key to recognizing data as a primary research output: https://www.ands.org.au/working-with-data/citation-and-identifiers/data-citation
Data dictionary: a list of key terms and metrics with definitions, a data glossary, which can help to define workflows: https://medium.com/@leapingllamas/data-dictionary-a-how-to-and-best-practices-a09a685dcd61
Data field heading: supplemental data placed at the beginning of a block of data being stored or transmitted - should be descriptive
Dataset: a collection of related sets of information that is composed of separate elements but can be manipulated by a computer
DMP: data management plan
DMP Tool: a tool used for creating data management plans. Access the tool at: https://dmptool.org/
DOI: a persistent identifier or handle used to identify objects uniquely, standardized by the International Organization for Standardization (ISO). Assigned DOIs resolve to the digital object to which they are assigned. Resolve a DOI at: https://www.doi.org/
Duplicability: the idea that research can be duplicated or replicated; as when an independent group of researchers copies a process and arrives at the same results as the original study; a method for establishing validity of results. Also referred to as replicability.
External drive: a portable storage device that can be attached to a computer through a wired connection or wirelessly
FERPA: Family Educational Rights and Privacy Act - affords students certain rights with respect to their educational records. See NDSU's Student Privacy Policy (FERPA).
Grant compliance: to ensure compliance with the terms of your grant, check in with the funding agency, NDSU, and the federal government's Grants 101 page at Grants.gov.
HIPAA: Health Insurance Portability and Accountability Act - specifically requires controls to protect covered data. Further information at Health Information Privacy, U.S. Department of Health and Human Services.
IR: institutional repository - a resource for providing storage and access to research generated at an institution. The NDSU Repository collects, preserves, and distributes digital content relating to North Dakota State University's mission, research, and scholarly activities.
IRB: Institutional Review Board- responsible for reviewing or certifying all research that includes human subjects prior to the start of the research project to ensure protection of participants' rights and welfare. NDSU's Institutional Review Board is part of the Office of Research and Creative Activity.
Markup language: a human-readable computer language that uses tags like HTML or XHTML
Metadata: a set of data that describes and provides information about other data; functions like a markup language
Metadata schema: a standardized structure for metadata. Commonly includes metadata components for information like dates, names, places, titles etc. Usually XML-based like Dublin Core, EAD, MODS, or disciplines-specific mark-up, etc. https://www.sciencedirect.com/topics/computer-science/metadata-schema
Network drive: a storage device on a local access network (LAN) - at NDSU S:, U:. and X:drives are common identifiers for network drives provided by campus IT. Check with ITS or your department to see if other network storage is available to you.
Raw data: data collected by research from first-hand sources; may be collected or generated by means of experimentation, surveys, or interviews and is collected specifically for a research project; may also be referred to as original, primary, or source data.
RCA: Office of Research and Creative Activity - centralized support, resources, and tools for all NDSU researchers.
Security: any data that contains information about human subjects needs to ensure privacy and confidentiality of that information: https://research-compliance.umich.edu/data-security-guidelines
URI: uniform resource identifier; a string of characters that unambiguously identifies a particular resource. NDSU uses the Handle.Net Registry.
Version control: a system that records changes to a file or set of files over time so that you can recall specific versions later: https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control